

Search Engines are very much sensitive to duplicate contents. Although they may not negatively harm your search engine ranking, these issues could drop down the potential for your posts to rank significantly.
Now you may ask, a bunch of news websites often quote to person in their news and since the quote remains same, don’t they get hurt by search Engines ? Let me make you clear on one thing, you should not worry about this, however having a large part of duplicate content and large number of pages with thin duplicate content is what we should worry about. However, today in this post, I will try to explain the reason why and how unknowingly webmasters face duplicate content issue withing their websites and how to overcome on-page duplicate content SEO issues.
Finding duplicate Contents
The first steps first, you should be able to find out duplicate contents before you could act against them. So how can you exactly know what contents are treated duplicate by search Engines ?
Google Webmaster Tools to Identify duplicate Contents
One of the easiest and efficient way to find out duplicate content in your website is Google Webmaster tool. You can find under Search Appeareances > HTML improvements, the screenshot below shows an example.
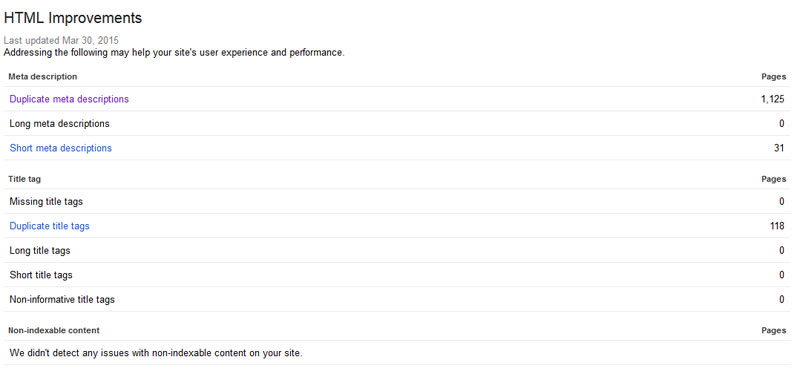
As you could see, the HTML suggestions in Google webmaster tools helps to show you duplicate titles and meta descriptions within your websites.
External Tools
Beside Google webmaster tools, there are different tools that would help to identify the duplicate content issues in the website, some of them are:
CopyScape
CopyScape is another online free tool which helps you to find the duplicate content in the web. Just visit Copyspace and enter your URL, it will show a list of matching pages if there are any.
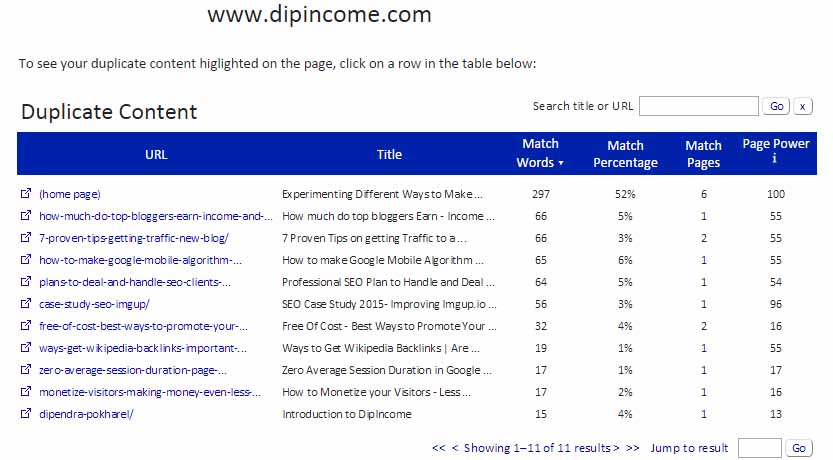
Siteliner
Siteliner is another great free tool that could help you detect duplicate contents within your website. The image below shows the repeating content issue in the homepage. Since the home page shows a list of recent posts with some of its contents, the match percent is 52% which is fine.
Reason and Fixing the issues
So now that you could find the duplicate content issues in your website, why do you think you should remove these ?
In my recent case study, eradicating duplicate contents in imgup was one of the reason why I could double the organic traffic in just two weeks after I took charge of its SEO.
Think of a crossroad where two similar sign points to the two direction;you are confused with which one is correct; similar is the case when you have duplicate content. Suppose example.com/post-title and example.com/category/post-title both leads to similar content. In this case search Engine is unsure about which would be the original one, in worst case, your links from other resources could be diversified and hence you could not enjoy the proper rank as much as you should.
The main reason for duplicate contents within your website is technical in most common Content management systems. You would never want to repeat the content in two different url until they are technical. However, the search engine crawlers are not artificial intelligent bots to solve your problem on your own which is why you will help to find out the duplicate contents and act accordingly.
Solution to the Issues
1. Deindex repeating Categories, Tags and Archives
In most of the wordpress issues, you must disallow search engines to crawl categories, tags or archives. However if you want to keep your categories indexed, you should add some unique descriptions in your categories which will be displayed in your categories page in your front end.
2. Using Canonical URLs or permanent Redirects
Sometimes you may not want to or could not remove all your duplicate contents, in that case you could use rel=’cannonical ‘.
Suppose you have a blog system and your article could be accessed through two categories url
a. https://blog.example.com/dresses/green-dresses-are-awesome
b. https://blog.example.com/green/green-dresses-are-awesome
<link rel=”canonical” href=”https://blog.example.com/dresses/green-dresses-are-awesome” />
Placing the above code inside the <head> section will alert the search engines that the link in b is a duplicate version of a and this will treat the link a as the original one
However you could also place a permanent redirect from link b to a as mentioned by Google’s John Mueller. So a 301 redirect would be more preferable.
3. WWW vs non-WWW preferred domain
Google and other search engines treat the www and the non-www versions of the same url differently. Your website could be accessed both as a example.com and www.example.com, so example.com is a copy of www.example.com or vice versa in eyes of search engines. So what you could do here is choose a preferred domain in Google webmaster tools(either one) and make a permanent redirection from the other to your preferred domain.
4. Using noIndex, follow tags
Using no index but follow tags in the links that should not be indexed. This would avoid search engines to index the pages in the database, however will crawl the links in the pages.
<head> <meta name="robots" content="noindex, follow" /> </head>
4. Avoiding duplicate contents
The steps above mentions a solution to duplicate content issues. You would however try to prevent these issues. Ask your webmaster to come up with a script that would allow your content to be accessed only through one URL.
Aditionally you could always disallow most common patterns via robots.txt pages.
User-agent: * Disallow: *?dir=* Disallow: *&order=* Disallow: *?price=*
Conclusions
On Page duplicate contents are very much common problem withing the webmasters. Although they do not encourage Google or other search engines to penalize your website, however it may lower down the potential to rank your blog posts or contents.
So you must take actions to solve the duplicate content issues in order to maintain a search engine friendly websites.






I read post. It was admirable.It is very interesting i like your effort.